Анализ временных рядов и прогнозирование в Excel на примере.
Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Размещено на http://www.allbest.ru/
Основные методы прогнозирования
Методы социального прогнозирования
Методы финансового прогнозирования
Методы экономического прогнозирования
Статистические методы прогнозирования
Экспертные методы прогнозирования
Анализ временных рядов
Структурные компоненты временного ряда
Основные методы прогнозирования
Прогнозирование - это предсказание будущего на основании накопленного опыта и текущих предположений относительно него.
Прогнозирование представляет собой сложный процесс, по ходу которого необходимо решать большое количество различных вопросов. Для его производства следует применять в сочетании различные методы прогнозирования , которых на сегодняшний день существует огромное множество, но на практике используются всего 15 - 20. На наиболее популярных из них мы и остановимся.
Метод экспертных оценок. Суть данного метода заключается в том, что в основе прогноза лежит мнение одного специалиста или группы специалистов, которое основано на профессиональном, практическом и научном опыте. Различают коллективные и индивидуальные экспертные оценки, часто используется при оценке персонала.
Метод экстраполяции. Основная идея экстраполяции - изучение сложившихся как в прошлом, так и настоящем стойких тенденций развития предприятия и перенос их на будущее. Различают прогнозную и формальную экстраполяцию. Формальная - основывается на предположении о том, что в будущем сохранятся прошлые и настоящие тенденции развития предприятия; при прогнозной - настоящее развитие увязывают с гипотезами о динамике предприятия с учетом того, что в будущем изменится влияние на него различных факторов. Следует знать, что методы экстраполяции лучше применять на начальной стадии прогнозирования, чтобы выявить тенденции изменения показателей.
Методы моделирования. Моделирование - это конструирование модели на основании предварительного изучения объекта и процессов, выделение его существенных признаков и характеристик. Прогнозирование с использованием моделей включает в себя ее разработку, экспериментальный анализ, сопоставление результатов предварительных прогнозных расчетов с фактическими данными состояния процесса или объекта, уточнение и корректировку модели.
Метод экономического прогнозирования (экономический анализ) заключается в том, что какой либо экономический процесс или явление, имеющие место на предприятии, расчленяются на части, после чего выявляется влияние и взаимосвязь этих частей на ход и развитие процесса, а также друг на друга. При помощи анализа можно раскрыть сущность такого процесса, а также определить закономерности его изменения в будущем, всесторонне оценить пути достижения поставленных целей. Поскольку экономический анализ - это необъемлемая часть и один из элементов логики прогнозирования, он должен осуществляться на макро-, мезо- и микроуровнях. Используется при планировании производства на предприятии. прогнозирование экономический временной экспертный
Процесс экономического анализа можно подразделить на несколько стадий:
* постановка проблемы, определение критериев оценки и целей;
* подготовка необходимой для анализа информации;
* аналитическая обработка информации после ее изучения;
* оформление результатов.
Балансовый метод. Данный метод основан на разработке балансов, которые представляют собой систему показателей, где первая часть, характеризующая ресурсы по источникам их поступления, равна второй, отражающей распределение их по всем направлениям расхода.
При помощи балансового метода воплощается в жизнь принцип пропорциональности и сбалансированности, который применяется при разработке прогнозов. Его суть заключается в увязке потребностей предприятия в различных видах сырьевых, материальных, финансовых и трудовых ресурсах с возможностями производства продукта и источниками ресурсов. Таким образом, система балансов, которую используют в прогнозировании, включает: финансовые, материальные и трудовые балансы. В каждую из данных групп входит еще ряд балансов.
Нормативный метод - один из основных методов прогнозирования. В настоящее время ему стало придаваться большое значение. Его сущность заключается в технико-экономических обоснованиях прогнозов с использованием нормативов и норм. Последние применяются при расчете потребности в ресурсах, а также показателей их использования.
Программно-целевой метод (ПЦМ). В сравнении с другими методами данный метод является сравнительно новым и недостаточно разработанным. Он начал широко применяться только в последние годы. ПЦМ тесно связан с уже рассмотренными методами и предполагает разработку прогноза начиная с оценки итоговых потребностей на основании целей развития предприятия при дальнейшем определении и поиске эффективных средств и путей их достижения, а также ресурсного обеспечения.
Суть ПМЦ заключается определении основных целей развития предприятия, разработки взаимосвязанных мероприятий по их достижению в заранее определенные сроки при сбалансированном обеспечении ресурсами, а также с учетом эффективного их использования.
Кроме прогнозирования, ПМЦ применяется при создании комплексных целевых программ, которые представляют собой документ, где отражены цель и комплекс производственных, организационно-хозяйственных, социальных и других мероприятий и заданий, увязанных по исполнителям, срокам осуществления и ресурсам.
Методы социального прогнозирования
Социальное прогнозирование как исследование с широким охватом объектов анализа опирается на множество методов. При классификации методов прогнозирования выделяются основные их признаки, позволяющие их структурировать по: степени формализации; принципу действия; способу получения информации.
Степень формализации в методах прогнозирования в зависимости от объекта исследования может быть различной; способы получения прогнозной информации многозначны, к ним следует отнести: методы ассоциативного моделирования, морфологический анализ, вероятностное моделирование, анкетирование, метод интервью, методы коллективной генерации идей, методы историко-логического анализа, написания сценариев и т.д. Наиболее распространенными методами социального прогнозирования являются методы экстраполяции, моделирования и экспертизы.
Экстраполяция означает распространение выводов, касающихся одной части какого-либо явления, на другую часть, на явление в целом, на будущее. Экстраполяция основывается на гипотезе о том, что ранее выявленные закономерности будут действовать в прогнозном периоде. Например, вывод об уровне развития какой-либо социальной группы можно сделать по наблюдениям за ее отдельными представителями, а о перспективах культуры - по тенденциям прошлого.
Экстраполяционный метод отличается многообразием - насчитывает не менее пяти различных вариантов. Статистическая экстраполяция - проекция роста населения по данным прошлого - это один из важнейших методов современного социального прогнозирования.
Моделирование - это метод исследования объектов познания на их аналогах - вещественных или мысленных.
Аналогом объекта может быть, например, его макет, чертеж, схема и т.д. В социальной сфере чаще используются мысленные модели. Работа с моделями позволяет перенести экспериментирование с реального социального объекта на его мысленно сконструированный дубликат и избежать риска неудачного, тем более опасного для людей управленческого решения. Главная особенность мысленной модели и состоит в том, что она может быть подвержена каким угодно испытаниям, которые практически состоят в том, что меняются параметры ее самой и среды, в которой она (как аналог реального объекта) существует. В этом огромное достоинство модели. Она может выступить и как образец, своего рода идеальный тип, приближение к которому может быть желательно для создателей проекта.
Самый практикуемый метод прогнозирования - экспертная оценка. По мнению Е.И.Холостовой, «экспертиза есть исследование трудноформализуемой задачи, которое осуществляется путем формирования мнения (подготовки заключения) специалиста, способного восполнить недостаток или несистемность информации по исследуемому вопросу своими знаниями, интуицией, опытом решения сходных задач и опорой на «здравый смысл».
Существуют такие сферы социальной жизни, в которых невозможно использовать другие методы прогнозирования , кроме экспертных. Прежде всего, это касается тех сфер, где отсутствует необходимая и достаточная информация о прошлом.
При экспертной оценке состояния либо отдельной социальной сферы, либо ее составляющего элемента, либо ее компонентов учитывается ряд обязательных положений, методических требований.
Прежде всего - оценка исходной ситуации:
Факторы, предопределяющие неудовлетворительное состояние;
Направления, тенденции, наиболее характерные для данного состояния ситуации;
Особенности, специфика развития наиболее важных составных;
Наиболее характерные формы работы, средства, с помощью которых осуществляется деятельность.
Второй блок вопросов включает в себя анализ деятельности тех организаций и служб, которые осуществляют эту деятельность. Оценка их деятельности идет по выявлению тенденций в их развитии, их рейтинга в общественном мнении.
Экспертную оценку проводят специальные центры экспертизы, научные информационно-аналитические центры, лаборатории экспертов, экспертные группы и отдельные эксперты.
Методика экспертной работы включает в себя ряд этапов:
Определяется круг экспертов;
Выявляются проблемы;
Намечается план и время действий;
Разрабатываются критерии для экспертных оценок;
Обозначаются формы и способы, в которых будут выражены результаты экспертизы (аналитическая записка, «круглый стол», конференция, публикации, выступления экспертов).
Итак, социальное прогнозирование опирается на различные методы исследования, основными из которых являются экстраполяция, моделирование и экспертиза.
Методы финансового прогнозирования
Финансовое прогнозирование по методу бюджетирования
Процесс бюджетирования является составной частью финансового планирования - процесса определения будущих действий по формированию и использованию финансовых ресурсов.
Бюджетирование - процесс построения и исполнения бюджета предприятия на основе бюджетов отдельных подразделений.
Бюджет - детализированный план деятельности предприятия на ближайший период, который охватывает доход от продаж, производственные и финансовые расходы, движение денежных средств, формирование прибыли предприятия.
Бюджеты подразделяются на два основных вида:
Операционный бюджет, отражающий текущую (производственную) деятельность предприятия;
Финансовый бюджет, представляющий собой прогноз финансовой отчетности.
План прибылей и убытков - основной документ операционного бюджета. Содержит данные о величине и структуре выручки от продаж, себестоимости реализованной продукции и конечных финансовых результатах.
Финансовый бюджет составляется с учетом информации, содержащейся в бюджете о прибылях и убытках.
Одним из основных этапов бюджетирования является прогнозирование движения денежных средств.
Бюджет движения денежных средств - это план денежных поступлений и платежей. При расчете бюджета движения денежных средств принципиально важно определить время поступлений и платежей, а не время исполнения хозяйственных операций.
Значение общего бюджета для предприятия раскрывается через следующие его функции:
Планирование операций, обеспечивающих достижение целей предприятия;
Координация различных видов деятельности и отдельных подразделений. Согласование интересов отдельных работников и групп в целом по предприятию;
Стимулирование руководителей всех рангов на достижение целей своих центров ответственности;
Контроль текущей деятельности, обеспечение плановой дисциплины;
Основа для оценки выполнения плана центрами ответственности и их руководителей;
Средство обучения менеджеров.
В отличие от формализованных отчетах о прибылях и убытках или бухгалтерского баланса, бюджет не имеет стандартизированной формы, которая должна строго соблюдаться. Бюджет может иметь бесконечное количество видов и форм. Форма и структура бюджета зависят от многих факторов: масштаба деятельности предприятия; достаточности и доступности исходной информации; состояния нормативной базы предприятия; от квалификации и опыта разработчика.
Финансовое прогнозирование по методу « процента от продаж
Существует два основнх метода финансового прогнозирования. Один из них - метод бюджетирования - представлен в разделе 3 методических указаний. Напомним, что он основан на концепции денежных потоков и его аналогом служит расчет финансовой части бизнес-плана.
Второй метод называется метод «процента от продаж» (первая модификация) или метод «формулы» (вторая модификация). Его преимущества - простота и лаконичность. Применяется для ориентировочных расчетов потребности во внешнем финансировании.
Факторы, оказывающие влияние на величину потребности в дополнительном финансировании:
Планируемый темп роста объема реализации;
Исходный уровень использования основных средств;
Капиталоемкость (ресурсоемкость) продукции;
Рентабельность продукции;
Дивидендная политика.
Метод «процента от продаж» - метод пропорциональной зависимости показателей деятельности предприятия от объема реализации.
Все вычисления по методу «процента от продаж» (методу «формулы») делаются на основе следующих предположений:
1. Переменные затраты, текущие активы и текущие обязательства при наращивании объема продаж на определенное количество процентов увеличиваются, в среднем, на столько же процентов. Это означает, что и текущие активы, и текущие пассивы будут составлять в плановом периоде прежний процент от выручки;
2. Процент увеличения стоимости основных средств рассчитывается под заданный процент наращивания оборота в соответствие с:
а) технологическими условиями бизнеса;
б) учетом наличия недогруженных основных средств на начало периода прогнозирования;
в) в соответствие со степенью материального и морального износа наличных основных средств и т.п.;
3. Долгосрочные обязательства и акционерный капитал берутся в прогноз неизменными;
4. Нераспределенная прибыль прогнозируется с учетом нормы распределения чистой прибыли на дивиденды и чистой рентабельности реализованной продукции.
Для прогнозирования нераспределенной прибыли к нераспределенной прибыли базового периода прибавляют прогнозируемую чистую прибыль и вычитают дивиденды.
Методы экономического прогнозирования
Особое место в классификации методов экономического прогнозирования занимают так называемые комбинированные методы, которые объединяют различные другие методы. Например, коллективные экспертные оценки и методы моделирования или статистические и опрос экспертов.
В качестве информации используется фактографическая и экспертная информация.
При классификации методов прогнозирования необходимо иметь в виду, что содержательная систематизация методов прогнозирования должна определяться самим объектом прогнозирования, экономическими процессами развития и их закономерностями.
С точки зрения оценки возможных результатов и путей прогнозного научно-технического развития прогнозы можно классифицировать по трем этапам: исследовательскому, программному и организационному.
Задачей исследовательского прогноза является определение возможных результатов будущего развития и выбор из множества возможных вариантов одного или нескольких положительных результатов. Так, например, развитие средств вычислительной техники можно отразить в росте их быстродействия, увеличении объема памяти и диапазона логических возможностей.
Основная цель этого этапа состоит в раскрытии широкой гаммы принципиально возможных перспектив в виде одной или ряда научно-технических проблем, подлежащих решению в течение прогнозируемого периода.
Программный аспект прогноза заключается в определении возможных путей достижения желаемых и необходимых результатов; ожидаемого по времени реализации каждого из возможных варианта и степени достоверности в успешном достижении некоторого результата по тому или иному варианту.
Организационная сторона прогноза включает в себя комплекс организационно-технических мероприятий, обеспечивающих достижение определенного результата по тому или иному варианту. В организационном аспекте исходят из представления о наличных экономических ресурсах и накопленном научном потенциале. Здесь должна быть сформулирована обоснованная гипотеза развития комплекса организационных параметров науки, дана вероятностная оценка рекомендуемой схеме распределения ресурсов и перспективам роста научного потенциала на прогнозируемый период.
Рассмотренные этапы научно-технического развития, как правило, выступают комплексно и находятся во взаимосвязи.
Статистические методы прогнозирования
Статистические методы прогнозирования охватывают разработку, изучение и применение современных математико-статистических методов прогнозирования на основе объективных данных (в том числе непараметрических методов наименьших квадратов с оцениванием точности прогноза, адаптивных методов, методов авторегрессии и других); развитие теории и практики вероятностно-статистического моделирования экспертных методов прогнозирования, в том числе методов анализа субъективных экспертных оценок на основе статистики нечисловых данных; разработку, изучение и применение методов прогнозирования в условиях риска и комбинированных методов прогнозирования с использованием совместно экономико-математических и эконометрических (как математико-статистических, так и экспертных) моделей. Научная база статистических методов прогнозирования -- прикладная статистика и теория принятия решений. Простейшие методы восстановления используемых для прогнозирования зависимостей исходят из заданного временного ряда, то есть функции, определенной в конечном числе точек на оси времени. При этом временной ряд часто рассматривается в рамках той или иной вероятностной модели, вводятся другие факторы (независимые переменные) помимо времени, напр., объем денежной массы. Временной ряд может быть многомерным. Основные решаемые задачи -- интерполяция и экстраполяция.
Метод наименьших квадратов в простейшем случае (линейная функция от одного фактора) был разработан К. Гауссом в 1794--1795 гг. Могут оказаться полезными предварительные преобразования переменных, например, логарифмирование. Наиболее часто используется метод наименьших квадратов при нескольких факторах.
Метод наименьших модулей, сплайны и другие методы экстраполяции применяются реже, хотя их статистические свойства зачастую лучше. Накоплен опыт прогнозирования индекса инфляции и стоимости потребительской корзины. Оказалось полезным преобразование (логарифмирование) переменной -- текущего индекса инфляции. Оценивание точности прогноза (в частности, с помощью доверительных интервалов) -- необходимая часть процедуры прогнозирования. Обычно используют вероятностно-статистические модели восстановления зависимости, напр., строят наилучший прогноз по методу максимального правдоподобия. Разработаны параметрические (обычно на основе модели нормальных ошибок) и непараметрические оценки точности прогноза и доверительные границы для него (на основе Центральной Предельной Теоремы теории вероятностей). Так, предложены непараметрические методы доверительного оценивания точки наложения (встречи) двух временных рядов для оценки динамики технического уровня собственной продукции и продукции конкурентов, представленной на мировом рынке. Применяются также эвристические приемы, не основанные на вероятностно статистической теории: метод скользящих средних, метод экспоненциального сглаживания.
Многомерная регрессия, в том числе с использованием непараметрических оценок плотности распределения, -- основной на настоящий момент статистический аппарат прогнозирования. Подчеркнем, что нереалистическое предположение о нормальности погрешностей измерений и отклонений от линии (поверхности) регрессии использовать не обязательно. Однако для отказа от предположения нормальности необходимо опереться на иной математический аппарат, основанный на многомерной Центральной Предельной Теореме теории вероятностей, технологии линеаризации и наследования сходимости. Он позволяет проводить точечное и интервальное оценивание параметров, проверять значимость их отличия от ноля в непараметрической постановке, строить доверительные границы для прогноза. Весьма важна проблема проверки адекватности модели, а также проблема отбора факторов. Априорный список факторов, оказывающих влияние на отклик, обычно весьма обширен. Его желательно сократить, и отдельное направление современных исследований посвящено методам отбора «информативного множества признаков». Однако эта проблема пока еще окончательно нерешена. Проявляются необычные эффекты. Так, установлено, что обычно используемые оценки степени полинома имеют в асимптотике геометрическое распределение. Перспективны непараметрические методы оценивания плотности вероятности и их применение для восстановления регрессионной зависимости произвольного вида. Наиболее общие результаты в этой области получены с помощью подходов статистики нечисловых данных. К современным статистическим методам прогнозирования относятся также модели авторегрессии, модель Бокса Дженкинса, системы эконометрических уравнений, основанные как на параметрических, так и на непараметрических подходах. Для установления возможности применения асимптотических результатов при конечных (т.н. «малых») объемах выборок полезны компьютерные статистические технологии. Они позволяют также строить различные имитационные модели. Отметим полезность методов размножения данных (бутстрепметодов). Системы прогнозирования с интенсивным использованием компьютеров объединяют различные методы прогнозирования в рамках единого автоматизированного рабочего места прогнозиста.
Прогнозирование на основе данных, имеющих нечисловую природу, например, прогнозирование качественных признаков основано на результатах статистики нечисловых данных. Весьма перспективными для прогнозирования представляются регрессионный анализ на основе интервальных данных, включающий, в частности, определение и расчет рационального объема выборки, а также регрессионный анализ нечетких данных. Общая постановка регрессионного анализа в рамках статистики нечисловых данных и ее частные случаи -- дисперсионный анализ и дискриминантный анализ (распознавание образов с учителем), -- давая единый подход к формально различным методам, полезны при программной реализации современных статистических методах прогнозирования. Основные процедуры обработки прогностических экспертных оценок -- проверка согласованности, кластер анализ и нахождение группового мнения.
Проверка согласованности мнений экспертов, выраженных ранжировками, проводится с помощью коэффициентов ранговой корреляции Кендалла и Спирмена, коэффициента ранговой конкордации Кендалла и Смита. Используются параметрические модели парных сравнений -- Терстоуна, БредлиТерриЛьюса -- и непараметрические модели теории люсианов. Полезна процедура согласования ранжировок и классификаций путем построения согласующих бинарных отношений. При отсутствии согласованности разбиение мнений экспертов на группы сходных между собой проводят методом ближайшего соседа или другими методами кластерного анализа (автоматического построения классификаций, распознавания образов без учителя). Классификация люсианов осуществляется на основе вероятностно-статистической модели. Используют также различные методы построения итогового мнения комиссии экспертов. Своей простотой выделяются методы средних арифметических и медиан рангов. Компьютерное моделирование позволило установить ряд свойств медианы Кемени, часто рекомендуемой для использования в качестве итогового (обобщенного, среднего) мнения комиссии экспертов в случае, когда их оценки даны в виде ранжировки.
Интерпретация закона больших чисел для нечисловых данных в терминах теории экспертного опроса такова: итоговое мнение устойчиво, т.е. мало меняется при изменении состава экспертной комиссии, и при росте числа экспертов приближается к «истине». При этом предполагается, что ответы экспертов можно рассматривать как результаты измерений с ошибками, все они -- независимые одинаково распределенные случайные элементы, вероятность принятия определенного значения убывает по мере удаления от некоторого центра -- «истины», а общее количество экспертов достаточно велико. В конкретных задачах прогнозирования необходимо провести классификацию рисков, поставить задачу оценивания конкретного риска, провести структуризацию риска, в частности, построить деревья причин (в другой терминологии, деревья отказов) и деревья последствий (деревья событий).
Центральной задачей является построение групповых и обобщенных показателей, например, показателей конкурентоспособности и качества. Риски необходимо учитывать при прогнозировании экономических последствий принимаемых решений, поведения потребителей и конкурентного окружения, внешнеэкономических условий и макроэкономического развития России, экологического состояния окружающей среды, безопасности технологий, экологической опасности промышленных и иных объектов. Современные компьютерные технологии прогнозирования основаны на интерактивных Статистические методы прогнозирования и использовании баз эконометрических данных, имитационных (в том числе на основе применения метода статистических испытаний) и экономико-математических динамических моделей, сочетающих экспертные, математико-статистические и моделирующие блоки.
Экспертные методы прогнозирования
Эксперт - квалифицированный специалист, привлекаемый для формирования оценок относительно объекта прогнозирования. Экспертная группа - коллектив экспертов, сформированный по определенным правилам. Суждение эксперта или экспертной группы относительно поставленной задачи прогноза называется экспертной оценкой; в первом случае используется термин «индивидуальная экспертная (прогнозная) оценка», а во втором - «коллективная экспертная (прогнозная) оценка». Способность эксперта создавать на базе профессиональных знаний, интуиции и опыта достоверные оценки относительно объекта прогнозирования характеризует его компетентность. Последняя имеет количественную меру, называемую коэффициентом компетентности. То же справедливо и в отношении экспертной группы: компетентность экспертной группы - это ее способность создавать достоверные оценки относительно объекта прогнозирования, адекватные мнению генеральной совокупности экспертов; количественная мера компетентности экспертной группы определяется на основе обобщения коэффициентов компетентности отдельных экспертов, входящих в группу.
Экспертный метод прогнозирования - метод прогнозирования, базирующийся на экспертной информации. В теоретическом аспекте правомерность использования экспертного метода подтверждается тем, что методологически правильно полученные экспертные суждения удовлетворяют двум общепринятым в науке критериям достоверности любого нового знания: точности и воспроизводимости результата. В таблице даны наименования и краткие характеристики основных экспертных методов, используемых при разработке социально-экономических прогнозов.
Анализ временных рядов
Цели, методы и этапы анализа временных рядов
Практическое изучение временного ряда предполагает выявление свойств ряда и получение выводов о вероятностном механизме, порождающем этот ряд. Основные цели при изучении временного ряда следующие:
Описание характерных особенностей ряда в сжатой форме;
Построение модели временного ряда;
Предсказание будущих значений на основе прошлых наблюдений;
Управление процессом, порождающим временной ряд, путем выборки сигналов, предупреждающих о грядущих неблагоприятных событиях.
Достижение поставленных целей возможно далеко не всегда как из-за недостатка исходных данных (недостаточная длительность наблюдения), так из-за изменчивости со временем статистической структуры ряда.
Перечисленные цели диктуют в значительной мере, последовательность этапов анализа временных рядов:
графическое представление и описание поведения ряда;
выделение и исключение закономерных, неслучайных составляющих ряда, зависящих от времени;
исследование случайной составляющей временного ряда, оставшейся после удаления закономерной составляющей;
построение (подбор) математической модели для описания случайной составляющей и проверка ее адекватности;
прогнозирование будущих значений ряда.
При анализе временных рядов используются различные методы, наиболее распространенными из которых являются:
корреляционный анализ, используемый для выявления характерных особенностей ряда (периодичностей, тенденций и т. д.);
спектральный анализ, позволяющий находить периодические составляющие временного ряда;
методы сглаживания и фильтрации, предназначенные для преобразования временных рядов с целью удаления высокочастотных и сезонных колебаний;
методы прогнозирования.
Структурные компоненты временного ряда
Как уже отмечалось, в модели временного ряда принято выделять две основные составляющие: детерминированную и случайную (рис.1). Под детерминированной составляющей временного ряда понимают числовую последовательность, элементы которой вычисляются по определенному правилу как функция времени t. Исключив детерминированную составляющую из данных, мы получим колеблющийся вокруг нуля ряд, который может в одном предельном случае представлять чисто случайные скачки, а в другом - плавное колебательное движение. В большинстве случаев будет нечто среднее: некоторая иррегулярность и определенный систематический эффект, обусловленный зависимостью последовательных членов ряда.
В свою очередь, детерминированная составляющая может содержать следующие структурные компоненты:
Тренд g, представляющий собой плавное изменение процесса во времени и обусловленный действием долговременных факторов. В качестве примера таких факторов в экономике можно назвать: а) изменение демографических характеристик популяции (численности, возрастной структуры); б) технологическое и экономическое развитие; в) рост потребления.
Сезонный эффект s, связанный с наличием факторов, действующих циклически с заранее известной периодичностью. Ряд в этом случае имеет иерархическую шкалу времени (например, внутри года есть сезоны, связанные с временами года, кварталы, месяцы) и в одноименных точках ряда имеют место сходные эффекты.
Размещено на Allbest.ru
...Подобные документы
Сущность экономического прогнозирования, характеристика основных форм предвидения. Предвидение внутренних и внешних условий деятельности. Виды прогнозов и технология прогнозирования. Методы прогнозирования: экспертные, статистические, комбинированные.
курсовая работа , добавлен 22.12.2009
Изучение методов прогнозирования развития: экстраполяции, балансового, нормативного и программно-целевого метода. Исследование организации работы эксперта, формирования анкет и таблиц экспертных оценок. Анализ математико-статистические моделей прогноза.
контрольная работа , добавлен 19.06.2011
Понятие, функции и методы прогнозирования – научно-обоснованного суждения о возможных состояниях объекта в будущем, об альтернативных путях и сроках их достижения. Классификация методов прогнозирования: социосинергетика, "коллективная генерация идей".
курсовая работа , добавлен 10.03.2011
Сущность основных понятий в области прогнозирования. Признаки классификации, виды прогнозов и их характеристика. Экстраполятивный и альтернативный подходы. Статистический и экспертный методы, их разновидности. Содержание и этапы разработки плана сбыта.
реферат , добавлен 25.01.2010
Сущность и структура системы социально-экономического прогнозирования, виды прогнозов и возможности их применения для предприятия. Мероприятия по планированию деятельности предприятия, их уровни и назначение. Экспертные методы, пути прогнозирования.
реферат , добавлен 27.06.2010
Суть форсайта как метода долгосрочного прогнозирования. Методы прогнозирования, применяемые в форсайтах. Критические технологии, экспертные панели. Особенности корпоративного форсайта. Применение метода корпоративных технологических "дорожных карт".
курсовая работа , добавлен 26.11.2014
Знакомство с основными проблемами прогнозирования, способы решения. Сглаживающие модели прогнозирования. Анализ подходов искусственного интеллекта: биологическая аналогия, архитектура сети, гибридные методы. Работа программы по прогнозу нейронных сетей.
дипломная работа , добавлен 27.06.2012
Методы прогнозирования, используемые в инновационном менеджменте. Шкалы и методы измерений в экспертном оценивании. Организация и проведение экспертизы. Получение обобщенной оценки на основе индивидуальных оценок экспертов, согласованность мнений.
курсовая работа , добавлен 07.05.2013
курсовая работа , добавлен 24.12.2011
Понятия прогнозирования и планирования. Почему прогнозировать сложно. Различные виды неопределенностей. Критерии классификации планирования. Основные техники и виды планирования. Основные методы прогнозирования. Планирование как управленческое решение.
Привет.
Я хочу рассказать об одной задаче, которая очень заинтересовала меня в свое время, а именно, о задаче прогнозирования временных рядов и решении этой задачи методом муравьиного алгоритма.
Для начала вкратце о задаче и о самом алгоритме:
Прогнозирование временных рядов подразумевает, что известно значение некой функции в первых n точках временного ряда. Используя эту информацию необходимо спрогнозировать значение в n+1 точке временного ряда. Существует множество различных методов прогнозирования, но на сегодняшний день одними из самых распространенных являются метод Винтерса и ARIMA модель. Подробнее о них можно почитать .
О том что такое муравьиный алгоритм говорилось уже довольно много. Для тех кому лень лезть, например, сюда , перескажу. Вкратце, муравьиный алгоритм это моделирование поведения муравьиной колонии в их стремлении найти кратчайший путь к источнику еды. Муравьи, при движении оставляют за собой след феромона, который влияет на вероятность выбора муравьем данного пути. Учитывая то, что муравьи будут за один и тот же промежуток времени пройти короткий путь бОльшее количество раз, на нем будет оставаться больше феромона. Таким образом, с течением времени, все больше муравьев будут выбирать кратчайший путь к источнику пищи.
Для наглядности, вставлю картинку:
Теперь, перейдем непосредственно к решению задачи прогнозирования методом муравьиных колоний.
Первая проблема с которой мы сталкиваемся - необходимо представить временной ряд в виде графа, на котором будем запускать муравьиный алгоритм.
Было найдено два возможных решения:
1. Представить временной ряд в виде мультиграфа где из каждой точки временного ряда можно перейти в каждую набором определенных приростов. (Для облегчения задачи будем брать нормализованные значения на промежутке от -1 до 1). Это был первый подход, который мы попробовали. Он показал неплохой результат на временных рядах малой размерности, но с увеличением размерности стала резко падать как точность прогноза, так и производительность, поэтому от этого варианта отказались.
2. Представить временной ряд в виде набора сцепленых графов, где каждый граф отвечает за свою величину прироста значения временного ряда. иначе говоря, имеем граф который отвечает за прирост -1, -0,9… и так до 1. Шаг, естественно, можно уменьшить, или увеличить, что скажется на точности прогноза и ресурсоемкости задачи.(в конечном итоге этот вариант оказался наиболее удачным.)
На этом наборе сцепленных графов, запускался муравьиный алгоритм(на каждом графе свой), который откладывал феромон на ребрах, соответствующих известным значениям временного ряда. Причем, при откладывании феромона на графе i, феромон также откладывался на графах i-1и i+1, но в гораздо меньшем количестве(в нашем случае 1/10 от базового количества феромона) таким образом, муравьи выделяли наиболее часто встречающиеся последовательности прироста значения временного ряда, а за счет откладывания феромона на смежные графы, нивелировалась возможная погрешность и изначальная зашумленность временного ряда.
Данный алгоритм мы тестировали на искусственно подготовленных временных рядах с разным уровнем периодичности и шума. Результат получился двояким. С одной стороны, при уровнях шума до 0,3 алгоритм показывает высокие результаты прогноза, сравнимые с результатами ARIMA модели. На более высоких уровнях шума возникает большой разброс результатов: прогноз то очень точный, то совершенно неправильный.
В настоящий момент мы работаем над подбором оптимального значения параметров алгоритма и некоторыми методами его улучшения, о которых я напишу как только они будут в достаточной степени проверены.
Спасибо всем за внимание.
Upd:
Постараюсь ответить на возникшие вопросы.
Мультиграф - это граф, каждая вершина которого соединена с каждой.
Хаотические ряды, как уже писали ниже, не случайны. Вы можете посмотреть на изображения ряда Лоренца в 3-х мерном пространстве и увидите цикличность движения. Просто определить эту цикличность сложно, и на первый взгляд ряд выглядит случайным.
Значения временного ряда нормализуются на промежутке -1...1 и записываются в граф. Граф - в данном случае таблица переходов из вершины в вершину. Феромон откладывается на ребра(в ячейки таблицы).
В случае со сцепленными графами используется несколько таблиц, каждая из которых отвечает только за свою величину перехода.
В зависимости от количества феромона в той, или иной ячейке, выбирается то, или иное значение временного ряда, как результат прогноза.
Алгоритм тестировали, преимущественно, на ряде Лоренца.
На данный момент рано говорить о том насколько он лучше или хуже. Похоже, что алгоритм подвержен нахождению псевдопериодов и с ростом уровня шума количество ложных периодов возрастает.
С другой стороны, при удачно подборе параметров точность прогноза достаточно высокая(отклонение до 7-10 процентов, что для хаотического ряда неплохо.)
К тестированию на реальных данным перейдем позже. Картинки постараюсь подготовить и добавить в ближайшее время.
Спасибо за внимание.
Данные за прошлые периоды можно использовать для прогнозирования.
Множество данных, где время является независимой переменной, называется временным рядом .
Общее изменение со временем результативного признака называется трендом . Мы рассмотрим модели линейного тренда , то есть параметры тренда модно рассчитать с помощью модели линейной регрессии.
Сезонная вариация – это повторение данных через небольшой промежуток времени. Под «сезоном» можно понимать день, и неделю, и месяц, и квартал. Если же промежуток времени будет длительным, то это – циклическая вариация . Мы остановимся на изучении данных для небольших интервалов времени, поэтому циклическую вариацию исключим из рассмотрения.
Сначала
на основании прошлых данных определяется
сезонная вариация. Исключив сезонную
вариацию (проведя так называемую
десезонализацию
данных
), с
помощью модели линейной регрессии
находим уравнение тренда. По уравнению
тренда и прошлым данным вычисляем
величины ошибок. Это среднее абсолютное
отклонение
 ,
где
,
где
 - это разность фактического и прогнозного
значений в момент времениt
, n
– число наблюдений.
- это разность фактического и прогнозного
значений в момент времениt
, n
– число наблюдений.
Анализ аддитивной модели.
Для аддитивной модели фактическое значение фактическое значение A = трендовое значение T + сезонная вариация S + ошибка E .
Пример 50 . Предположим, что нам известен объем прожаж (тыс. руб.) за последние 11 кварталов. Дадим на основании этих данных прогноз объема продаж на следующие два квартала.
|
Номер квартала |
Объем продаж |
Оценка сезонной вариации |
||
Заполним следующую таблицу. Оценки сезонной вариации запишем под соответствующим номером квартала году. В каждом столбце вычисляем среднее значение оценок сезонной вариации = (сумма чисел в столбце)/ (количество чисел в столбце). Результат запишем в строке «Среднее» (округления взяты до одной цифры после запятой). Сумма чисел в строке «Среднее» = -1.
Скорректируем значения в строке «Среднее», чтобы общая сумма была равна 0. Это необходимо, чтобы усреднить значения сезонной вариации в целом за год. Корректирующий фактор вычисляется следующим образом: сумма оценок сезонных вариаций (-1) делится на число кварталов в году (4). Поэтому из каждого числа этой строки нужно вычесть -1/4= -0,25. Так как у нас округления до одной цифры после запятой, то из нечетных столбцов вычтем -0,3, а из четных столбцов вычтем -0,2. В последней строке получены значения сезонной вариации для соответствующего квартала года.
|
Номер квартала в году | ||||||
|
Номер квартала |
Объем продаж |
Сезонная вариация |
A - S = T + E |
Уравнение
линии тренда T
=
a
+
b
*
x
,
где
 -
номерi
-
го квартала.
-
номерi
-
го квартала.
Найдем коэффициенты a и b


где
 -
номерi
-
го квартала, а
-
номерi
-
го квартала, а
 -
значение сезонной вариацииi
-
го квартала.
-
значение сезонной вариацииi
-
го квартала.
|
Номер квартала |
x 2 | |||
a =1,9 и b =1,1.
T = 1,9+ 1,1 x .
 i
i
 ,
где
,
где
 -
объем продаж,
-
объем продаж, -
сезонная вариация,
-
сезонная вариация, -
трендовое значение вi
-ом
квартале.
-
трендовое значение вi
-ом
квартале.
i x
Составим таблицу
|
Объем продаж A |
Десезонализированный объем продаж A - S = T + E |
Трендовое значение |
Ошибка
|
|
|
|



И среднеквадратическая ошибка
Прогноз объема продаж в 12-м квартале: (1,9+1,1*12)+(-0,9)=14,2 тыс.руб.
Прогноз объема продаж в 13-м квартале: (1,9+1,1*13)+2=18,2 тыс.руб.
Задача 50. В таблице указан объем продаж (тыс. руб.) за последние 11 кварталов. Дать на основании этих данных прогноз объема продаж на следующие два квартала.
На первом шаге нужно исключить влияние сезонной вариации. Воспользуемся методом скользящей средней. Заполним таблицу.
|
Номер квартала |
Объем продаж |
Скользящая средняя за 4 квартала |
Центрированная скользящая средняя |
Оценка сезонной вариации |
1 год = 4 квартала. Поэтому найдем среднее значение объема продаж за 4 последовательных квартала. Для этого нужно сложить 4 последовательных числа из 2-го столбца (объем продаж), эту сумму умножить на 4 (количество слагаемых) и результат записать в 3-й столбец напротив 3-го слагаемого.
Если при заполнении 3-го скользящая средняя вычислялась для четного числа сезонов, то вычисляется центрированная скользящая средняя по следующему правилу: полусумму двух соседних чисел из 3-го столбца запишем в четвертый столбец напротив верхнего из них. В противном случае (если скользящая средняя вычислялась для нечетного числа сезонов) центрированную скользящую среднюю вычислять не надо.
5-й столбец (оценка сезонной вариации) – это разность объема продаж и скользящей средней, в случае если последняя вычислялась для нечетно числа сезонов или разность объема продаж и центрированной скользящей средней в противном случае.
Заполним следующую таблицу. Оценки сезонной вариации запишем под соответствующим номером квартала году. В каждом столбце вычисляем среднее значение оценок сезонной вариации = (сумма чисел в столбце)/ (количество чисел в столбце). Результат запишем в строке «Среднее» (округления взяты до одной цифры после запятой). Сумма чисел в строке «Среднее» .
Скорректируем значения в строке «Среднее», чтобы общая сумма была равна 0. Это необходимо, чтобы усреднить значения сезонной вариации в целом за год. Корректирующий фактор вычисляется следующим образом: сумма оценок сезонных вариаций. Поэтому из каждого числа этой строки нужно вычесть = 0,593. В последней строке получены значения сезонной вариации для соответствующего квартала года.
|
Номер квартала в году | ||||||
|
Скорректированная сезонная вариация | ||||||
Исключим сезонную вариацию из фактических данных. Проведем десезонализацию данных.
|
Номер квартала |
Объем продаж |
Сезонная вариация |
Десезонализированный объем продаж A - S = T + E |
Из чисел 2-го столбца вычитаем числа 3-го столбца и результат пишем в 4-м столбце.
Уравнение
линии тренда T
=
a
+
b
*
x
,
где
 -
номерi
-
го квартала.
-
номерi
-
го квартала.
Найдем коэффициенты a и b по данным следующим формулам:


где
 -
номерi
-
го квартала, а
-
номерi
-
го квартала, а
 -
значение сезонной вариацииi
-
го квартала.
-
значение сезонной вариацииi
-
го квартала.
Для упрощения расчетов по указанным формулам заполним таблицу
|
Номер квартала |
x 2 | |||
Подставляя соответствующие данные из таблицы в приведенные выше формулы получим: a =1,97 и b =1,12.
Итак, уравнение тренда запишется так T = 1,97+ 1,12 x .
Теперь займемся расчетом ошибок.
Для
этого необходимо найти величины
 -
разность фактического и прогнозного
значения вi
-ом
квартале по следующей формуле:
-
разность фактического и прогнозного
значения вi
-ом
квартале по следующей формуле:
 ,
где
,
где
 -
объем продаж,
-
объем продаж, -
сезонная вариация,
-
сезонная вариация, -
трендовое значение вi
-ом
квартале.
-
трендовое значение вi
-ом
квартале.
Чтобы вычислить трендовое значение в i -ом квартале воспользуемся соответствующей формулой приведенной выше подставляя в нее вместо x номер соответствующего квартала.
Составим таблицу
|
Объем продаж A |
Десезонализированный объем продаж A - S = T + E |
Трендовое значение |
Ошибка
|
|
|
|



Среднее абсолютное отклонение и среднеквадратическая ошибка . Мы видим, что ошибки достаточно велики. Это скажется на качестве прогноза.
Дадим прогноз объема продаж на следующие два квартала.
прогноз = трендовое значение + скорректированная сезонная вариация.
Мы считаем, что тенденция, выявленная по прошлым данным, сохранится и в ближайшем будущем. Подставляем номера кварталов в формулу и учитываем скорректированную сезонную вариацию. T = 1,97+ 1,12 x .
Прогноз объема продаж в 12-м квартале: (1,97+1,12*12)+(-0,453)=14,957 тыс.руб.
Прогноз объема продаж в 13-м квартале: (1,97+1,12*13)+ 1,047=17,577 тыс.руб.
Методы прогнозирования временных рядов
1. Прогнозирование как задача анализа временного ряда. Детерминированная и случайная составляющие: способы их выделения и оценки.
Прогнозирование – это научное выявление вероятностных путей и результатов предстоящего развития явлений и процессов, оценка показателей процессов для более или менее отдаленного будущего.
Изменение состояния наблюдаемого явления (процесса) характеризуется совокупностью параметров x1, x2, … , xt,…, измеренных в последовательные моменты времени. Такая последовательность называется временным рядом.
Анализ временных рядов – одно из направлений науки прогнозирования.
Если одновременно рассматриваются несколько характеристик процесса, то в этом случае говорят о многомерных временных рядах.
Под детерминированной (закономерной) составляющей временного ряда x1, x2, … , xn понимается числовая последовательность d1, d2, … , dn, элементы которой вычисляются по определенному правилу как функция времени t.
Если исключить из ряда детерминированную составляющую, то оставшаяся часть будет выглядеть хаотично. Ее называют случайной компонентой ε1, ε2, … , εn.
Модели разложения временного ряда на детерминированную и случайную компоненты:
1. Аддитивная модель:
xt = dt + εt, t=1,…n
2. Мультипликативная модель:
xt = dt · εt, t=1,…n
Если мультипликативную модель прологарифмировать, то получим аддитивную модель для логарифмов xt.
В детерминированной компоненте выделяют:
1) Тренд (trt) – плавно изменяющаяся нециклическая компонента, описывающая чистое влияние долговременных факторов, эффект которых сказывается постепенно.
2) Сезонная компонента (St) – отражает повторяемость процессов во времени.
3) Циклическая компонента (Ct) – описывает длительные периоды относительного подъема и спада.
4) Интервенция – существенное кратковременное воздействие на временной ряд.
Модели тренда:
– линейная: trt = b0 + b1t
– нелинейные модели:
полиномиальная: trt = b0 + b1t + b2t2 + … + bntn
логарифмическая: trt = b0 + b1 ln(t)
логистическая:
экспоненциальная: trt = b0 · b1t
параболическая: trt = b0 + b1t + b2t2
гиперболическая: trt = b0 + b1 /t
Тренд используется для долгосрочного прогноза.
Выделение тренда:
1) Метод наименьших квадратов (время – фактор, временной ряд – зависимая переменная):
xti = f (ti, θ)+εt i=1,…n
f – функция тренда;
θ – неизвестные параметры модели временного ряда.
εt – независимые и одинаково распределенные случайные величины.
Если минимизировать функцию, можно найти параметры θ.
2) Применение разностных операторов
![]()
Выделение сезонных эффектов
Пусть m – число периодов, p – величина периода.
St = St+p, для любых t.
1) Оценка сезонной компоненты
а) Сезонные эффекты на фоне тренда
Для аддитивной модели xt = trt + St + εt оценка:
Если необходимо, чтобы сумма сезонных эффектов равнялась 0, то переходят к скорректированным оценкам сезонных эффектов:

Для мультипликативной модели xt = trt * St * εt:

б) При наличии в ряде циклической компоненты (метод скользящих средних)
Идея метода: каждое значение исходного ВР заменяется средним значением на интервале времени, длина которого выбирается заранее. Выбранный интервал как бы скользит вдоль ряда.
Скользящее среднее при медианном сглаживании: t=med (xt-m,xt-m+1, …,xt+m)
При средне арифметическом сглаживании:
xt=1/(2m+1)(xt-m+xt-m+1+…+xt+m), если р – четный,
xt=1/(2m)(1/2*xt-m+xt-m+1+…+1/2*xt+m) если р – нечетный.
Для аддитивной модели xt = trt +Ct + St + εt.
Для упрощения обозначений: начнем нумерацию величин с единицы, изменим нумерацию исходного ряда так, чтобы величине x соответствовал член xt.
– скользящее среднее с периодом p, построенное по xt.
Для мультипликативной модели – перейти к логарифмам и получить мультипликативную модель.
xt = trt · Ct · St · εt
yt = log xt, dt = log trt, gt = log Ct, rt = log St, δt = log εt
yt = dt + gt + rt + δt
2) Удаление сезонной компоненты (сезонное выравнивание)
а) При наличии оценок сезонной компоненты:
Для аддитивной модели – путем вычитания из начальных значений ряда полученных сезонных оценок .
Для мультипликативной модели – путем деления начальных значений ряда на соответствующие сезонные оценки и умножением на 100%.
б) Применение разностных операторов
где В – оператор сдвига назад.
Разностный оператор второго порядка:
Если ВР одновременно содержит тренд и сезонную компоненту, то их удаление возможно с помощью последовательного применения простых и сезонных разностных операторов. Порядок их применения не существенен:
3) Прогнозирование с помощью сезонной компоненты:
Для аддитивной модели:
![]()
Для мультипликативной модели:

2. Модели временного ряда: AR(p), MA(q), ARIMA(p,d,q). Идентификация моделей, оценка параметров, исследование адекватности модели, прогнозирование.
Для описания вероятностной компоненты временного ряда используют понятие случайного процесса.
Случайным процессом x(t), заданным на множестве Т, называют функцию от t, значения которой при каждом t T являются случайной величиной.
Случайные процессы, у которых вероятностные свойства не изменяются во времени, называются стационарными (матожидание и дисперсия – константы).
В качестве модели стационарных временных рядов чаще всего используются:
Скользящее среднее;
Их комбинации.
Для проверки стационарности ряда остатков и оценки его дисперсии используют:
Выборочную автокорреляционную функцию (коррелограмму);
Частную автокорреляционную функцию.
Пусть εt – процесс белого шума, т.е. в разные моменты времени t случайные величины εt независимы и одинаково распределены с параметрами M(εt)=0, D(εt)=σ2=const. Тогда:
Случайный процесс x(t) со средним значением μ называется процессом авторегрессии порядка p (AR(p)), если для него выполняется соотношение:
x(t)-μ= α1 (x(t-1) – μ) + α2 (x(t-2) – μ) +…+ αp (x(t-p) – μ) + εt
Случайный процесс x(t) называется процессом скользящего среднего порядка q (MA(q)), если для него выполняется соотношение:
x(t)= εt + β1 εt-1 +…+ βq εt-q
Случайный процесс x(t) называется процессом авторегрессии-скользящего среднего порядков p и q (ARMA(p,q)), если для него выполняется соотношение:
Нестационарные технические и экономические процессы могут быть описаны модифицированной моделью ARMA(p,q). Для удаления тренда можно использовать разностные операторы.
Пусть даны две последовательности U=(…,U-1,U0,U1,…) и V=(…,V-1, V0,V1,V2,…) такие, что:
Означает ,для
![]() означает и т.д.
означает и т.д.
Тогда процесс AR(p) представляется в виде ,
MA(q): ![]() ,
,
ARMA(p,q): ![]()
B можно использовать как разностный оператор, т.е. ![]()
эквивалентно V=(1-B)U
Для разностей второго порядка:
z =(1-B)V=(1-B)2U

где – разностный оператор порядка d; x=(1-B)dx.
Идентифицировать модель – определить ее параметры p, d и q. Для идентификации модели служат графики частных автокорреляционных (АКФ) и частных автокорреляционных функций (ЧАКФ).
АКФ. k-й член АКФ определяется по формуле:
 (*)
(*)
Параметр k называют лагом. На практике k < n/4. График АКФ – коррелограмма. Если полученный ряд остатков нестационарный, то по коррелограмма можно определить причины нестационарности.
Значения ЧАКФ akk находят, решая систему Юла – Уолкера, используя значения АКФ
Система Юла – Уолкера:
R1 = a1 + a2*r1 + … + ap*rp-1
r2 = a1*r1 + a2 + … + ap*rp-2
………………………………..
rp = a1*rp-1 + a2*rp-2 + …+ ap
После визуализации ряда и удаления тренда рассматривается АКФ. Если график АКФ не имеет тенденции к затуханию, то это нестационарный процесс (модель ARIMA). При наличии сезонных колебаний коррелограмма содержит периодические всплески, как правило, соответствующие периоду колебаний. Рассматриваются разности 1-го, 2-го,…k-го порядка, пока ряд не станет стационарным, тогда параметр d=k (обычно k не больше 2). Переходят к идентификации стационарной модели.
Идентификация стационарных моделей:
АКФ плавно спадает;
ЧАКФ обрывается на лаге p.
АКФ обрывается на лаге q.
ЧАКФ плавно спадает.
Оценка параметров m, ai модели AR(p):
В качестве оценки m можно взять среднее значении ВР

Для оценки ai найдем корреляцию между X(t) и X(t-k):
Общее решение этого уравнения относительно rk определяется корнями характеристического уравнения
Пусть корни характеристического уравнения различны. Тогда общее решение может быть записано в виде:
Из требования стационарности следует, что все |λi|<1.
Если записать уравнение (**) для k=1, 2, 3…., получим систему Юла-Уоркера для AR(p) процесса:
r1 = a1 +a2*r1 + … + ap*rp-1
r2 = a1*r1 + a2 + … + ap*rp-2
………………………………..
rp = a1*rp-1 + a2*rp-2 + …+ap
Решая эту систему относительно a1, a2....ap, получим параметры AR(p).
Оценка параметра βi модели MA(q):
Для процесса МА(q) при |k| > q Cov = 0.
Cov = s2*(bk + b1*bk+1 + b2*bk+2 + … + bq-k*bq)
Отсюда автокорреляционная функция имеет вид:
 (***)
(***)
Для оценивания коэффициентов bi по наблюденному участку траектории существует несколько путей. Наиболее простой:
Находят
коэффициенты корреляции ![]() по формуле (*). Из
системы (***) получают систему нелинейных уравнений для нахождения bi. Она решается
итерационными методами.
по формуле (*). Из
системы (***) получают систему нелинейных уравнений для нахождения bi. Она решается
итерационными методами.
Прогнозирование. При прогнозировании необходимо получить детерминированные значения ВР по уже имеющимся формулам, а затем рассчитать случайные значения по подобранной модели и скорректировать детерминированные значения на величину случайных значений.
3. Прогнозирование с помощью искусственных нейронных сетей, метод окон.
Решение математических задач с помощью нейронных сетей (НС) осуществляется путем обучение НС способам решения этих задач.
Обучение многослойной нейронной сети производится методом обратного распространения ошибки (Back Propagation).
Модель искусственного нейрона

где xi – входные сигналы,
ai – коэффициенты проводимости (const), которые корректируются в процессе обучения,
F – функция активации, она нелинейная, в разных моделях может называться по-разному. Например, «сигмоида»:
Общая структура нейронной сети:
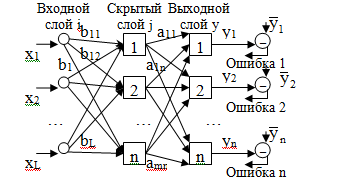
Скрытых слоев может быть несколько, поэтому НС – многослойная.
– вектор эталонных сигналов (желаемых)
yi – вектор реальных (выходных) сигналов
xi – вектор входных сигналов.
Стратегия обучения «обучение с учителем»
Типовые шаги:
1) Выбрать очередную обучающую пару из обучающего множества .
x – входной вектор;
– соответствующий ему желаемый (выходной вектор).
Подать входной вектор х на вход НС.
2) Вычислить выход сети у – реальный выходной сигнал.
Предварительно, весовые коэффициенты aij и bij задаются произвольно случайным образом.
3) Вычислить отклонение (ошибку): ![]()
4) Подкорректировать веса aij и bij сети так, чтобы минимизировать ошибку.
![]()
5) Повторить шаги 1– 4.
Процесс повторяется до тех пор, пока ошибка на всем обучающем множестве не уменьшится до требуемой величины.
Проход вперед сигнала X по сети:
Из обучающего множества берется пара. Для каждого слоя, начиная с первого, вычисляется Y: Y = F(X·A),
где A – матрица весов слоя;
F – функция активации.
Вычисления – слой за слоем.
Обратный проход ошибки по НС:
Выполняется подстройка весов выходного слоя. Для этого применяется модифицируемое дельта-правило.
Рис. Обучение одного веса от нейрона p в скрытом слое j к нейрону q в выходном слое k
Для выходного нейрона сначала находится сигнал ошибки
![]()
εq умножается на производную сжимающей функции , вычисленную для этого нейрона слоя k. Получаем величину δ:
Δapqk = α · δqk · ypj,
где α – коэффициент скорости обучения (0.01≤ α <1) – const, подбирается экспериментально в процесса обучения.
ypj – выходной сигнал нейрона p слоя j.
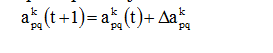 – величина веса в
связке нейронов p→q на шаге t (до
коррекции) и шаге t+1 (после коррекции).
– величина веса в
связке нейронов p→q на шаге t (до
коррекции) и шаге t+1 (после коррекции).
Подстройка весов скрытого слоя.
Рассмотрим нейрон скрытого слоя p. При переходе вперед этот нейрон передает свой выходной сигнал нейронам выходного слоя через соединяющие их веса. Во время обучения эти веса функционируют в обратном порядке, пропуская величину δ от выхода назад к скрытому слою.
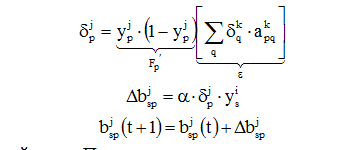
И так для каждой пары. Процесс заканчивается, если для каждого X НС будет вырабатывать
Прогнозирование с помощью НС. Метод окон.
Задан временной ряд xt, t=1,2…T. Задача прогнозирования сводится к задаче распознавания образов на НС.
Метод выявления закономерности во временном ряде на основе НС называется “windowing” (метод окон).
Используется два окна Wi (input) и Wo (output) фиксированного размера n и m соответственно, для наблюдаемого множества данных.

Эти окна способны перемещаться с некоторым шагом S по кривой (ряду) вдоль оси времени. В результате получается некоторая последовательность наблюдений:

Первое окно Wi, сканирует данные, предает их на вход НС, а Wo – на выход. Получающаяся на каждом шаге пара Wji→Wj0, j=1..n образует обучающую пару (наблюдение). После обучения НС можно использовать для прогноза.
Скачать полный текст диссертации в формате PDF (2.9 Мб).
Глава 1. Постановка задачи и обзор моделей прогнозирования временных рядов
В текст диссертации включены вставки со ссылками на полезные записи блога, в которых я простым языком рассказываю о моделях прогнозирования и привожу примеры реализации.Нейронные сети рассмотрены в наборе записей по тэгу .
- Модель ARIMAX подробно описана в четырех записях по тэгу .
- Описание и примеры реализации экспоненциального сглаживания приведены по тэгу .
- Опубликованы записи по вопросам .
- Полный перечень материалов о моделях прогнозирования смотри по тэгу .
Слово прогноз возникло от греческого , что означает предвидение, предсказание. Под прогнозированием понимают предсказание будущего с помощью научных методов . Процессом прогнозирования называется специальное научное исследование конкретных перспектив развития какого-либо процесса. Согласно работе процессы, перспективы которых необходимо предсказывать, чаще всего описываются временными рядами , то есть последовательностью значений некоторых величин, полученных в определенные моменты времени. Временной ряд включает в себя два обязательных элемента - отметку времени и значение показателя ряда, полученное тем или иным способом и соответствующее указанной отметке времени. Каждый временной ряд рассматривается как выборочная реализация из бесконечной популяции, генерируемой стохастическим процессом, на который оказывают влияние множество факторов . На представлен пример временного ряда цен на электроэнергию европейской территории РФ.

Рис. 1.1 Временной ряд цен на электроэнергию
Простым языком о видах временных рядов смотри запись блога Характеристики прогнозируемых временных рядов
Одна из классификаций временных рядов приведена в работе . Согласно этой работе, временные ряды различаются способом определения значения, временным шагом, памятью и стационарностью.
- интервальные временные ряды ,
- моментные временные ряды .
Интервальный временной ряд представляет собой последовательность, в которой уровень явления (значение временного ряда) относят к результату, накопленному или вновь произведенному за определенный интервал времени. Интервальным, например, является временной ряд показателя выпуска продукции предприятием за неделю, месяц или год; объем воды, сброшенной гидроэлектростанцией за час, день, месяц; объем электроэнергии, произведенной за час, день, месяц и другие.
Если же значение временного ряда характеризует изучаемое явление в конкретный момент времени, то совокупность таких значений образует моментный временной ряд . Примерами моментных рядов являются последовательности финансовых индексов, рыночных цен; физические показатели, такие как температура окружающего воздуха, влажность, давление, измеренные в конкретные моменты времени, и другие.
В зависимости от частоты определения значений временного ряда, они делятся на
- равноотстоящие временные ряды ,
- неравноотстоящие временные ряды .
Равноотстоящие временные ряды формируются при исследовании и фиксации значений процесса в следующие друг за другом равные интервалы времени. Большинство физических процессов описываются при помощи равноотстоящих временных рядов. Неравноотстоящими временными рядами называются те ряды, для которых принцип равенства интервалов фиксации значений не выполняется. К таким рядам относятся, например, все биржевые индексы в связи с тем, что их значения определяются лишь в рабочие дни недели.
В зависимости от характера описываемого процесса временные ряды разделяются на
- временные ряды длинной памяти ,
- временные ряды короткой памяти .
Задача отнесения временного ряда к рядам с короткой или длинной памятью описана в статье . В целом, говоря о временных рядах с длинной памятью , подразумеваются временные ряды, для которых автокорреляционная функция, введенная в книге , убывает медленно. К временным рядам с короткой памятью относят временные ряды, автокорреляционная функция которых убывает быстро. Скорость потока транспорта по дорогам, а также многие физические процессы, такие как потребление электроэнергии, температура воздуха, относятся к временным рядам с длинной памятью . К временным рядам с короткой памятью относятся, например, временные ряды биржевых индексов.
Дополнительно временные ряды принято разделять на
- стационарные временные ряды ,
- нестационарные временные ряды .
Стационарным временным рядом называется такой ряд, который остается в равновесии относительно постоянного среднего уровня. Остальные временные ряды являются нестационарными . В книге указано, что и в промышленности, и в торговле, и в экономике, где прогнозирование имеет важное значение, многие временные ряды являются нестационарными, то есть не имеющими естественного среднего значения. Нестационарные временные ряды для решения задачи прогнозирования часто приводятся к стационарным при помощи разностного оператора .
Горизонты прогнозирования рассмотрены также в записи блога Горизонты прогнозирования временных рядов
- ультра: до 3 – 4 часа;
- краткосрочное прогнозирование : до 5 – 8 часов;
- : до 16 – 24 часов.
Для задачи прогнозирования энергопотребления классификация задач предложена в работе :
- : до одного дня;
- краткосрочное прогнозирование : от одного дня до недели;
- среднесрочное прогнозирование : от одной недели до года;
- долгосрочное прогнозирование : более чем на год вперед.
То есть для различных временных рядов , с различным временным разрешением классификация срочности задач прогнозирования индивидуальна .
Говоря о прогнозировании временных рядов, необходимо различить два взаимосвязанных понятия - метод прогнозирования и .
Метод прогнозирования представляет собой последовательность действий , которые нужно совершить для получения модели прогнозирования временного ряда.
Метод прогнозирования содержит последовательность действий, в результате выполнения которой определяется конкретного временного ряда. Кроме того, метод прогнозирования содержит действия по оценке качества прогнозных значений. Общий итеративный подход к построению модели прогнозирования состоит из следующий шагов .
Шаг 1. На первом шаге на основании предыдущего собственного или стороннего опыта выбирается общий класс моделей для прогнозирования временного ряда на заданный горизонт.
Шаг 2. Определенный общий класс моделей обширен. Для непосредственной подгонки к исходному временному ряду, развиваются грубые методы идентификации подклассов моделей. Такие методы идентификации используют качественные оценки временного ряда.
Шаг 3. После определения подкласса модели, необходимо оценить ее параметры , если модель содержит параметры, или структуру, если модель относится к категории структурных моделей (). На данном этапе обычно используется итеративные способы, когда производится оценка участка (или всего) временного ряда при различных значениях изменяемых величин. Как правило, данный шаг является наиболее трудоемким в связи с тем, что часто в расчет принимаются все доступные исторические значения временного ряда.
Шаг 4. Далее производится диагностическая проверка полученной модели прогнозирования . Чаще всего выбирается участок или несколько участков временного ряда, достаточных по длине для проверочного прогнозирования и последующей оценки точности прогноза. Выбранные для диагностики модели прогнозирования участки временного ряда называются контрольными участками (периодами).
Шаг 5. В случае если точность диагностического прогнозирования оказалась приемлемой для задач, в которых используются прогнозные значения, то модель готова к использованию . В случае если точность прогнозирования оказалось недостаточной для последующего использования прогнозных значений, то возможно итеративное повторение всех описанных выше шагов, начиная с первого.
Моделью прогнозирования временного ряда является функциональное представление, адекватно описывающее временной ряд.
При прогнозировании временных рядов возможны два варианта постановки задачи . В первом варианте для получения будущих значений исследуемого временного ряда используются доступные значения только этого ряда . Во втором варианте для получения прогнозных значений возможно использование не только фактических значений искомого ряда, но и значений набора внешних факторов, представленных в виде временных рядов . В общем случае временные ряды внешних факторов могут иметь разрешение по времени отличное от разрешения искомого временного ряда. Например, в работе подробно обсуждаются внешние факторы, оказывающие влияние на временной ряд энергопотребления. К таким внешним факторам относят температуру окружающей среды, влажность воздуха, а также сезонность, т. е. час суток, день недели, месяц года. В общем случае внешние факторы могут быть дискретными , т. е. представленными временными рядами, например, температура воздуха; или категориальными , т. е. состоящими из подмножеств, например, в зависимости от веса тела человека можно отнести к трем категориям: «легкий», «средний», «тяжелый». Лишь некоторые модели прогнозирования позволяют учитывать категориальные внешние факторы, большинство моделей позволяют учитывать только дискретных ().
При прогнозировании временного ряда , адекватно описывающую временной ряд, которая называется моделью прогнозирования . Цель создания модели прогнозирования состоит в получении такой модели, для которой среднее абсолютное отклонение истинного значения от прогнозируемого стремится к минимальному для заданного горизонта, который называется временем упреждения. После того, как модель прогнозирования временного ряда определена, требуется вычислить будущие значения временного ряда, а также их доверительный интервал.
1.2. Формальная постановка задачи
Прогнозирование без учета внешних факторов . Пусть значения временного ряда доступны в дискретные моменты времени t = 1,2,...,T . Обозначим временной ряд Z(t) = Z(1), Z(2),...,Z(T) . В момент времени T необходимо определить значения процесса Z(t) в моменты времени T+1,...,T+P . Момент времени T называется моментом прогноза, а величина P - временем упреждения .
1) Для вычисления значений временного ряда в будущие моменты времени требуется определить функциональную зависимость , отражающую связь между прошлыми и будущими значениями этого ряда

Рис. 1.2. Иллюстрация задачи прогнозирования временного ряда без учета внешних факторов
Прогнозирование с учетом внешних факторов . Пусть значения исходного временного ряда Z(t) доступны в дискретные моменты времени t = 1,2,...,T . Предполагается, что на значения Z(t) оказывает влияние набор внешних факторов. Пусть первый внешний фактор X 1 (t 1) доступен в дискретные моменты времени t 1 = 1,2,...,T 1 , второй внешний фактор X 2 (t 2) доступен в моменты времени t 2 = 1,2,...,T 2 и т.д.
В случае, если дискретность исходного временного ряда и внешних факторов, а также значения T,T 1 ,...,T S различны, то временные ряды внешних факторов X 1 (t 1) ,...,X S (t S) необходимо привести к единой шкале времени t .
В момент прогноза T необходимо определить будущие значения исходного процесса Z(t) в моменты времени T+1,...,T+P , учитывая влияние внешних факторов X 1 (t) ,...,X S (t) . При этом считаем, что значения внешних факторов в моменты времени X 1 (T+1) ,...,X 1 (T+P) ,...,X S (T+1) ,...,X S (T+P) являются доступными.
1) Для вычисления будущих значений процесса Z(t) в указанные моменты времени требуется определить функциональную зависимость , отражающую связь между прошлыми значениями Z(t) и будущими, а также принимающую во внимание влияние внешних факторов X 1 (t) ,...,X S (t) на исходный временной ряд
2) Кроме получения будущих значений требуется определить доверительный интервал возможных отклонений этих значений.
Задача прогнозирования временного ряда с учетом одного внешнего фактора представлена на

Рис. 1.3. Иллюстрация задачи прогнозирования временного ряда с учетом внешнего фактора
1.3. Обзор моделей прогнозирования
Перед тем как перейти к обзору моделей, необходимо отметить, что названия моделей и соответствующих методов как правило совпадают . Например, работы , , , посвящены одной из самых распространенных моделей прогнозирования авторегрессия проинтегрированного скользящего среднего с учетом внешнего фактора (auto regression moving average external, ). Эту модель и соответствующий ей метод обычно называют . В настоящее время принято использовать английские аббревиатуры названий как моделей, так и методов.
Набор понятных для чтения материалов по вопросу классификации моделей и методов прогнозирования временных рядов можно найти по тегу .
Линейная регрессионная модель . Самым простым вариантом регрессионной модели является линейная регрессия. В основу модели положено предположение, что существует дискретный внешний фактор X(t) , оказывающий влияние на исследуемый процесс Z(t) , при этом связь между процессом и внешним фактором линейна. Модель прогнозирования на основании линейной регрессии описывается уравнением
где α 0 и α 1 - коэффициенты регрессии; ε t - ошибка модели. Для получения прогнозных значений Z(t) в момент времени t необходимо иметь значение X(t) в тот же момент времени t , что редко выполнимо на практике.
Множественная регрессионная модель . На практике на процесс Z(t) оказывают влияние целый ряд дискретных внешних факторов X 1 (t) ,…,X S (t) . Тогда модель прогнозирования имеет вид
Недостатком данной модели является то, что для вычисления будущего значения процесса Z(t) необходимо знать будущие значения всех факторов X 1 (t) ,…,X S (t) , что почти невыполнимо на практике.
В основу нелинейной регрессионной модели положено предположение о том, что существует известная функция, описывающая зависимость между исходным процессом Z(t) и внешним фактором X(t)
В рамках построения модели прогнозирования необходимо определить параметры функции A . Например, можно предположить, что
Для построения модели достаточно определить параметры ![]() . Однако на практике редко встречаются процессы, для которых вид функциональной зависимости между процессом Z(t)
и внешним фактором X(t)
заранее известен. В связи с этим нелинейные регрессионные модели применяются редко
.
. Однако на практике редко встречаются процессы, для которых вид функциональной зависимости между процессом Z(t)
и внешним фактором X(t)
заранее известен. В связи с этим нелинейные регрессионные модели применяются редко
.
Модель группового учета аргументов (МГУА) была разработана Ивахтенко А.Г. . Модель имеет вид
 (1.9)
(1.9)
Другой тип модели имеет большое значение в описании временных рядов и часто используется совместно с авторегрессией называется моделью скользящего среднего порядка q и описывается уравнением
Авторегрессионнная модель с распределенным лагом (autoregressive distributed lag models, ARDLM) недостаточно подробно описана в литературе. Основное внимание данной модели уделяется в книгах по эконометрике .
Часто при моделировании процессов на изучаемую переменную влияют не только текущие значения процесса, но и его лаги, то есть значения временного ряда, предшествующие изучаемому моменту времени. Модель авторегрессии распределенного лага описывается уравнением
Здесь φ 0 ,..., φ p - коэффициенты, l - величина лага. Модель () называется ARDLM(p,l) и чаще всего применяется для моделирования экономических процессов .
1.3.3. Модели экспоненциального сглаживания
Примеры реализации экспоненциального сглаживания можно найти по тэгу .
Модели экспоненциального сглаживания разработаны в середине XX века и до сегодняшнего дня являются широко распространенными в силу их простоты и наглядности.
Модель экспоненциального сглаживания (exponential smoothing, ES) применяется для моделирования финансовых и экономических процессов . В основу экспоненциального сглаживания заложена идея постоянного пересмотра прогнозных значений по мере поступления фактических. Модель ES присваивает экспоненциально убывающие веса наблюдениям по мере их старения. Таким образом, последние доступные наблюдения имеют большее влияние на прогнозное значение, чем старшие наблюдения.
Функция модели ES имеет вид
где α - коэффициент сглаживания, 0 < α < 1 ; начальные условия определяются как S(1) = Z(0) . В данной модели каждое последующее сглаженное значение S(t) является взвешенным средним между предыдущим значением временного ряда Z(t) и предыдущего сглаженного значения S(t-1) .
Модель Хольта или двойное экспоненциальное сглаживание применяется для моделирования процессов, имеющих тренд . В этом случае в модели необходимо рассматривать две составляющие: уровень и тренд . Уровень и тренд сглаживаются отдельно
 (1.17)
(1.17)
Здесь α - коэффициент сглаживания уровня, как и в модели (1.16), γ - коэффициент сглаживания тренда.
Модель Хольта-Винтерса или тройное экспоненциальное сглаживание применяется для процессов, которые имеют тренд и сезонную составляющую
Здесь R(t) - сглаженный уровень без учета сезонной составляющей
G(t) - сглаженный тренд
а S(t) - сезонная составляющая
Величина L определяется длиной сезона исследуемого процесса. Модели экспоненциального сглаживания наиболее популярны для долгосрочного прогнозирования .
1.3.4. Нейросетевые модели
Набор читабельных материалов с примерами реализации нейронных сетей можно найти по тэгу
В настоящее время самой популярной среди структурных моделей является модель на основе искусственных нейронных сетей (artificial neural network, ANN) . Нейронные сети состоят из нейронов ().

Рис. 1.4. Нелинейная модель нейрона
Модель нейрона можно описать парой уравнений
 (1.22)
(1.22)
где Z(t-1) ,...,Z(t-m) - входные сигналы; ω 1 ,...,ω m - синаптические веса нейрона; p - порог; φ(U(t)) - функция активации.
Функция активации бывают трех основных типов :
- функция единичного скачка ;
- кусочно-линейная функция ;
- сигмоидальная функция .
Способ связи нейронов определяет архитектуру нейронной сети . Согласно работе , в зависимости от способа связи нейронов сети делятся на
- однослойные нейронные сети прямого распространения ,
- многослойные нейронные сети прямого распространения ,
- рекуррентные нейронные сети .

Рис. 1.5. Трехслойная нейронная сеть прямого распространения
Таким образом, при помощи нейронных сетей возможно моделирование нелинейной зависимости будущего значения временного ряда от его фактических значений и от значений внешних факторов. Нелинейная зависимость определяется структурой сети и функцией активации.
Пример реализации в MATLAB трехслойной нейронной сети для прогнозирования энергопотребоения на 24 значения вперед можно найти в записи блога Создаем нейронную сеть для прогнозирования временного ряда .
1.3.5. Модели на базе цепей Маркова
Модели прогнозирования на основе цепей Маркова (Markov chain model) предполагают, что будущее состояние процесса зависит только от его текущего состояния и не зависит от предыдущих . В связи с этим процессы, моделируемые цепями Маркова, должны относиться к процессами с короткой памятью.
Пример цепи Маркова для процесса, имеющего три состояния , представлен на .

Рис. 1.6. Цепь Маркова с тремя состояниями
Здесь S 1 ,...,X 3 - состояния процесса Z(t) ; λ 12 S 1 в состояние S 2 , λ 23 - вероятность перехода из состояния S 2 в состояние S 3 и т.д. При построении цепи Маркова определяется множество состояний и вероятности переходов. Есть текущее состояние процесса S i , то качестве будущего состояния процесса выбирается такое состояние S i , вероятность перехода в которое (значение λ ij ) максимальна.
Таким образом, структура цепи Маркова и вероятности перехода состояний определяют зависимость между будущим значением процесса и его текущим значением .
1.3.6. Модели на базе классификационно-регрессионных деревьев
Классификационно-регрессионные деревья (classification and regression trees, CART) являются еще одной популярной структурной моделью прогнозирования временных рядов . Структурные модели CART разработаны для моделирования процессов, на которые оказывают влияние как непрерывные внешние факторы, так и категориальные. Если внешние факторы, влияющие на процесс Z(t) , непрерывны, то используются регрессионные деревья; если факторы категориальные, то - классификационные деревья. В случае, если необходимо учитывать факторы обоих типов, то используются смешанные классификационно-регрессионные деревья.

Рис. 1.7. Бинарное классификационно-регрессионное дерево
Согласно модели CART, прогнозное значение временного ряда зависит от предыдущих значений, а также некоторых независимых переменных. На приведенном на примере сначала предыдущее значение процесса сравнивается с константой Z 0 . Если значение Z(t-1) меньше Z 0 , то выполняется следующая проверка: X(t) > X 11 . Если неравенство не выполняется, то Z(t) = C 3 , иначе проверки продолжаются до того момента, пока не будет найден лист дерева, в котором происходит определение будущего значения процесса Z(t) . Важно, что при определении значения в расчет принимаются как непрерывные переменные, например, X(t) , так и категориальные Y , для которых выполняется проверка присутствия значения в одном из заранее определенных подмножеств. Значения пороговых констант, например, Z 0 , X 11 , а также подмножеств Y 11 ,Y 12 выполняется на этапе обучения дерева .
Таким образом, CART моделирует зависимость будущей величины процесса Z(t) при помощи структуры дерева, а также пороговых констант и подмножеств .
1.1.1. Другие модели и методы прогнозирования
Кроме классов моделей прогнозирования , рассмотренных выше, существуют менее распространенные модели и методы прогнозирования . Главным недостатком моделей и методов , упомянутых в настоящем разделе, является недостаточная методологическая база , т. е. недостаточно подробное описание возможностей как моделей, так и путей определения их параметров. Кроме того, в открытом доступе можно найти лишь небольшое количество статей, посвященных применению данных методов.
Метод опорных векторов (support vector machine, SVM) применяется, например, для прогнозирования движения рынков и цен на электроэнергию . В основу метода положена классификация, производимая за счет перевода исходных временных рядов, представленных в виде векторов, в пространство более высокой размерности и поиска разделяющей гиперплоскости с максимальным зазором в этом пространстве. Алгоритм SVM работает в предположении, что чем больше разница или расстояние между этими параллельными гиперплоскостями, тем меньше будет средняя ошибка классификатора . При этом задача прогнозирования решается таким образом, что на этапе обучения классификатора выявляются независимые переменные (внешние факторы), будущие значения которых определяют в какой из определенных ранее подклассов попадет прогноз Z(t) .
Генетический алгоритм (genetic algorithm, GA) был разработан и часто применяется для решения задач оптимизации, а также поисковых задач. Однако некоторые модификации GA позволяют решать задачи прогнозирования.
Важными являются их простота и прозрачность моделирования. Еще одним достоинством является единообразие анализа и проектирования, заложенное в работе . На сегодняшний день данный класс моделей является одним из наиболее популярных , а потому в открытом доступе легко найти примеры применения авторегрессионных моделей для решения задач прогнозирования временных рядов различных предметных областей.
Недостатками данного класса моделей являются: большое число параметров модели, идентификация которых неоднозначна и ресурсоемка ; низкая адаптивность моделей, а также линейность и, как следствие, отсутствие способности моделирования нелинейных процессов, часто встречающихся на практике .
. Достоинствами данного класса моделей являются простота и единообразие их анализа и проектирования. Данный класс моделей чаще других используется для долгосрочного прогнозирования .
Недостатком данного класса моделей прогнозирования является отсутствие гибкости .
Нейросетевые модели и методы . Основным достоинством нейросетевых моделей является нелинейность, т.е. способность устанавливать нелинейные зависимости между будущими и фактическими значениями процессов. Другими важными достоинствами являются: адаптивность, масштабируемость (параллельная структура ANN ускоряет вычисления) и единообразие их анализа и проектирования .
При этом недостатками ANN являются отсутствие прозрачности моделирования; сложность выбора архитектуры, высокие требования к непротиворечивости обучающей выборки; сложность выбора алгоритма обучения и ресурсоемкость процесса их обучения .
Простота и единообразие анализа и проектирования являются достоинствами моделей на базе цепей Маркова .
Недостатком данных моделей является отсутствие возможности моделирования процессов с длинной памятью .
Модели на базе классификационно-регрессионных деревьев . Достоинствами данного класса моделей являются: масштабируемость, за счет которой возможна быстрая обработка сверхбольших объемов данных; быстрота и однозначность процесса обучения дерева (в отличие от ANN) , а также возможность использовать категориальные внешние факторы.
Недостатками данных моделей являются неоднозначность алгоритма построения структуры дерева; сложность вопроса останова т.е. вопроса о том, когда стоит прекратить дальнейшие ветвления; отсутствие единообразия их анализа и проектирования .
Достоинства и недостатки моделей и методов систематизированы в таблице 1.
Таблица 1. Сравнение моделей и методов прогнозирования
| Модель и метод | Достоинства | Недостатки |
|---|---|---|
| Регрессионные модели и методы | простота, гибкость, прозрачность моделирования; единообразие анализа и проектирования | сложность определения функциональной зависимости; трудоемкость нахождения коэффициентов зависимости; отсутствие возможности моделирования нелинейных процессов (для нелинейной регрессии) |
| Авторегрессионные модели и методы | простота, прозрачность моделирования; единообразие анализа и проектирования; множество примеров применения | трудоемкость и ресурсоемкость идентификации моделей; невозможность моделирования нелинейностей; низкая адаптивность |
| Модели и методы экспоненциального сглаживания | недостаточная гибкость; узкая применимость моделей | |
| Нейросетевые модели и методы | нелинейность моделей; масштабируемость, высокая адаптивность; единообразие анализа и проектирования; множество примеров применения | отсутствие прозрачности; сложность выбора архитектуры; жесткие требования к обучающей выборке; сложность выбора алгоритма обучения; ресурсоемкость процесса обучения |
| Модели и методы на базе цепей Маркова | простота моделирования; единообразие анализа и проектирования | невозможность моделирования процессов с длинной памятью; узкая применимость моделей |
| Модели и методы на базе классификационно-регрессионных деревьев | масштабируемость; быстрота и простота процесса обучения; возможность учитывать категориальные переменные | неоднозначность алгоритма построения дерева; сложность вопроса останова |
Нужно дополнительно отметить, что ни для одной из рассмотренных групп моделей (и методов) в достоинствах не указана точность прогнозирования . Это сделано в связи с тем, что точность прогнозирования того или иного процесса зависит не только от модели , но и от опыта исследователя , от доступности данных , от располагаемой аппаратной мощности и многих других факторов. Точность прогнозирования будет оцениваться для конкретных задач , решаемых в рамках данной работы.
В ряде работ , , указано, что на сегодняшний день наиболее распространенными моделями прогнозирования являются авторегрессионные модели (ARIMAX), а также нейросетевые модели (ANN) . В статье , в частности, утверждается: «Without a doubt ARIMA(X) and GRACH modeling methodologies are the most popular methodologies for forecasting time series. Neural networks are now the biggest challengers to conventional time series forecasting methods» . (Без сомнений модели ARIMA(X) и GARCH являются самыми популярными для прогнозирования временных рядов. В настоящее время главную конкуренцию данным моделям составляют модели на основе ANN .)
1.4.2. Комбинированные модели
Одной из популярных современных тенденций в области создания моделей прогнозирования является создание комбинированных моделей и методов . Подобный подход дает возможность компенсировать недостатки одних моделей при помощи других и направлен на повышение точности прогнозирования, как одного из главных критериев эффективности модели.
Одной из первых работ в этой области является статья . В ней предлагается подход, в котором прогнозирование временного ряда осуществляется в два этапа . На первом этапе на основании моделей распознавания образов (pattern recognition) выделяются гомогенные группы (patterns) временного ряда . На следующем этапе для каждой группы строится отдельная модель прогнозирования . В статье указывается, что при комбинированном подходе удается повысить точность прогнозирования временных рядов .
В работе предлагается модель для прогнозирования цен на электроэнергию Испании. При помощи вейвлет преобразования (wavelet transform) доступные значения временного ряда разделяются на несколько последовательностей, для каждой из которых строится отдельная модель ARIMA.
В обзоре моделей прогнозирования энергопотребления рассматривается следующие типы комбинаций:
- нейронные сети + нечеткая логика ;
- нейронные сети + ARIMA ;
- нейронные сети + регрессия ;
- нейронные сети + GA + нечеткая логика ;
- регрессия + нечеткая логика .
В большинстве комбинаций модели на основе нейронных сетей применяются для решения задачи кластеризации , а далее для каждого кластера строиться отдельная модель прогнозирования на основе ARIMA, GA, нечеткой логики и др. В работе утверждается, что применение комбинированных моделей , выполняющих предварительную кластеризации и последующее прогнозирование внутри определенного кластера, является наиболее перспективным направлением развития моделей прогнозирования .
Работа посвящена вопросам кластеризации временных рядов для того, чтобы на основании полученных кластеров выполнять прогнозирование. Для кластеризации предлагается два метода: метод K- cредних (K-mean) и метод нечетких C-средних (fuzzy C-mean). Целью обоих алгоритмов кластеризации является извлечение полезной информации из временного ряда для последующего прогнозирования. Авторы утверждают, что применение кластеризации дает возможность повысить точность прогнозирования.
Применение комбинированных моделей является направлением, которое при корректном подходе позволяет повысить точность прогнозирования . Главным недостатком комбинированных моделей является сложность и ресурсоемкость их разработки : нужно разработать модели таким образом, чтобы компенсировать недостатки каждой из них, не потеряв достоинств.
Ряд исследователей пошли по альтернативному пути и разработали авторегрессионные модели , в основе которых лежит предположение о том, что временной ряд есть последовательность повторяющихся кластеров (patterns). Однако при этом разработчики не создавали комбинированных моделей, а определяли кластеры и выполняли прогноз на основании одной модели . Рассмотрим эти модели подробнее.
В работе предложена модель прогнозирования направления движения индексов рынка (index movement), учитывающая кластеры временного ряда. Пусть временной ряд содержит три значения -1, 0 и 1, которые характеризуют спад, стабильное состояние и подъем рынка соответственно. Кластером (pattern) называется последовательность для i = 1,2,...,N-M , где N - число доступных отчетов временного ряда Z(t) . Для определения прогнозного значения рассмотрена последняя доступная информация, а именно последовательность Z(N,M) = Z(N-M+1),Z(N-M+2),...,Z(N) , для которой определена ближайшая похожая (closet match) Z(Q,M) = Z(Q+1),Z(Q+2),...,Z(Q+M) . При этом функция, определяющая близость, имеет вид
т.е. близость кластеров определяется простым сравнением. Далее вычисляется прогнозное значение
Таким образом, в данной модели предполагается, что если в некоторый момент времени в прошлом рынок вел себя определенным образом, то в будущем его поведение повторится в связи с тем, что временной ряд является последовательностью кластеров.
Еще в двух работах , предложена модель прогнозирования, основанная на модели авторегрессии, но принимающая во внимание кусочки временного ряда . Здесь прогнозное значение временного ряда определено выражением
которое является линейной авторегрессией порядка M . При этом коэффициенты авторегрессии α 0 ,α 1 ,…,α M определяются следующим образом. Предполагается, что существует K кусочков (векторов) длины M временного ряда, для которых выполняется выражение
 (1.28)
(1.28)
При определении ближайших векторов (closest vectors) Z(i 1 -1) ,Z(i 1 -2) ,…,Z(i 1 -M) ,...,Z(i K -1) ,Z(i K -2) ,…,Z(i K -M) в статье использовано значение линейной корреляции Пирсона между всеми возможными векторами и новейшим вектором (last available vector) Z(t-1) , а также, , является перспективным в области создания моделей прогнозирования временных рядов . Предложенная в диссертации модель прогнозирования развивает модели , , и устраняет все перечисленные выше недостатки: модель позволяет учитывать влияния внешних факторов; формулируется критерий определения похожей выборки для двух видов постановок задачи прогнозирования (); количество параметром модели сокращается до одного, что существенно упрощает идентификацию модели.
1.5. Выводы
1) Задача прогнозирования временных рядов имеет высокую актуальность для многих предметных областей и является неотъемлемой частью повседневной работы многих компаний.
2) Установлено, что к настоящему времени разработано множество моделей для решения задачи прогнозирования временного ряда , среди которых наибольшую применимость имеют авторегрессионные и нейросетевые модели .
3) Выявлены достоинства и недостатки рассмотренных моделей . Установлено, что существенным недостатком авторегрессионных моделей является большое число свободных параметров, требующих идентификации; недостатками нейросетевых моделей является ее непрозрачность моделирования и сложность обучения сети.
4) Определено, что наиболее перспективным направлением развития моделей прогнозирования с целью повышения точности является создание комбинированных моделей , выполняющих на первом этапе кластеризацию, а затем прогнозирование временного ряда внутри установленного кластера.